Görüntüyü geliştirme, netleştirme, uygun şekillerde 2 boyutlu veya 3 boyutlu olarak görüntüleme, görüntüdeki kenarları/sınırları tespit etme, bölgesel analizler, görüntüyü dönüştürme, bölütleme, yerleştirme, nesne tanıma, hareket tespiti gibi işlemler son zamanlarda çeşitli alanlarda ve uygulamalarda sıkça kullanılan görüntü işleme yöntemlerinin başında gelmektedir. Görüntü işleme algoritmaları sosyal ağ uygulamaları içerisinde eğlence ve hobi için kullanılmakla birlikte, elektronik cihazların ve toplum güvenliğinin sağlanması amacı ile parmak izi tanıma, yüz tanıma ve retina tanıma gibi özelleştirilmiş yöntemler ile artık hemen hemen her türlü işlemi elektronik sistemler üzerinden tamamladığımız bu günlerde, bilgi güvenliğinin artırılması amacı ile birçok uygulama içerisinde de kullanılarak son dönemde önemini artırmıştır. Bu çalışmada özel olarak yüz tanıma algoritmaları üzerinde çalışılmış, ilgili kişilere ait fotoğrafların doğru sınıflandırılması sırasında hız ve doğruluk oranı ölçümleri yapılmıştır. Kullanılan yöntemler temel bileşen analizi (tba), destek vektör makineleri (DVM), K- en yakın komşu algoritması(KYK), sinir ağları ile örüntü tanıma ve derin öğrenme olarak listelenebilir.
VERİ SETİ
Veri Setimizde 38 farklı kişinin sahip olduğu 65 fotoğraf bulunmaktadır (Yale Face Database, 2020). Her kişinin farklı açılardan farklı mimikler ile çekilmiş fotoğraflarından oluşan veri setinde her fotoğraf 192 satır 168 sütundan oluşan matrisler halinde 32 KB yer tutarak hafızada toplamda 84.5MB yer kaplamaktadır. Veri setinde bulunan kişilerin fotoğraflarından oluşan örneği Şekil 1’de bulabilirsiniz.
Veri setinde toplam 2469 fotoğraf bulunmaktadır. Bu fotoğrafların %25’i oluşturulan modeli test için, %75 ise modelin eğitimi ve oluşturulması için kullanılmıştır. Veri setinin eğitim ve test için ikiye ayrılması modelin başarısı için önem arz etmektedir. Eğer eğitim setine veya test setine dahil olan veriler çoğunlukla aynı gruba ait olursa, modelin doğru eğitilme ve veriyi doğru sınıflandırma ihtimali düşmektedir. Bu sebeple, bu aşamada rastgele önem arz etmektedir. Verinin sınıf kategorilerinden sıralı olarak seçilmesi, ilgili veri setine aynı sınıfa ait verilerin çoğunluklu olarak ayrılmasına ve çeşitliliğin azalmasına böylelikle sınıflandırma başarısının düşmesine neden olabilmektedir. Bu sebeple veri setinden rasgele seçimler yapılarak oransal olarak eşit dağılımların oluşması sağlanmıştır
VERİ ÖN İŞLEME
Veri ön işleme aşaması, makine öğrenmesi yöntemleri kadar zaman alan ve modelin performansını bu yöntemler kadar etkileyen bir bölümdür. Veri ön işleme aşamaları genellikle veri setinde Şekil 1 Çalışmada kullanılan veri setinden örnek yüzler ARGE Dergisi 05 eksik veri olan örneklerin varlığı, var olan örneklerin sayısal olarak yeterliliği, veriye ait özelliklerin aldığı değerler sebebi ile normalizasyona ihtiyacı olup olmadığı, kullanılacak makine öğrenmesi yöntemine uygun girdi formatına sahip olup olmadığı gibi analizlerden oluşmaktadır. Bu çalışmada veri seti bir fotoğraf veri tabanından oluşmakta ve verilere ait özelliklerde eksik veri bulunmamaktadır. Toplam veri sayısı 2469 olup algoritmaların performans analizi için yeterli bir sayıdır. Ancak bu tip çalışmalarda en büyük sorun fotoğrafların boyutu ve sayısı sebebi ile hafızada kapladığı alan ve bu büyük veriyi işlemek için gerekli zaman ve donanım yetersizliğidir. Bu sebeple çalışmamızda temel bileşen analizi yöntemini kullanarak fotoğraf boyutu %75 azaltılmıştır. Böylelikle gereken hafıza, işlem süresi ve modelin performansı orijinal ve boyutu azaltılmış fotoğraf için karşılaştırmalı olarak analiz edilebilmiştir.
Temel bileşen analizi çok ve birbiri ile bağlantılı değişkenlerden oluşan veriyi en az bilgi kaybıyla ifade edebilen bileşenlere dönüştürme işlemidir. Analizin bir başka özelliği ise boyutu azaltılmış verinin gerektiğinde orijinal veriye geri dönüştürülebilir olmasıdır. Şekil 2’de orijinal ve temel bileşen analizi ile %25 oranına küçültülmüş halini görebilirsiniz.

küçültülmüş fotoğraf örneği
Bu yöntem ile birlikte 192×168 olan fotoğraf boyutu 48×42’ye düşürülerek fotoğrafı en iyi ifade eden bileşenleri kullanılmıştır. Bu bileşenler, verinin varyans ve kovaryans değerleri hesaplanarak oluşan özdeğer ve özvektörler ile elde edilmektedir.
YÖNTEMLER
Bu çalışma Intel Core i7-7700 HQ, 2.80Ghz CPU, 1GB GPU ve 16 GB Ram kapasiteli bilgisayar ile MATLAB 2019b kullanılarak tamamlanmıştır.
a) Destek Vektör Makineleri ve K- En Yakın Komşu Yöntemi
Veri ön işleme aşamasında elde ettiğimiz boyutu azaltılmış veri ile orijinal fotoğraflardan oluşan veri seti üzerinde Destek Vektör Makineleri (DVM) ve K-en yakın komşu yöntemleri (KYK) ayrı ayrı uygulanarak, doğru sınıflandırma performansı ve işlemler için gerekli zaman ölçülmüştür.
DVM yöntemi istatistiksel bir yöntem olup, gözetimli öğrenme algoritmalarındandır. Yüksek boyutlu verilerde/düzlemlerde etkili olan bu yöntem iki değişkenli sınıflarda olduğu gibi 2’den fazla sınıf değişkeni olduğu durumlarda da tercih edilmektedir. DVM farklı sınıflara ait verileri oluşturduğu hiper düzlemler ile birbirinden ayırmaktadır. Doğrusal ve doğrusal olmayan veriler için de kullanmak mümkündür. Bu çalışmada MATLAB 2019b içerisinde bulunan ‘Statistics and Machine Learning Toolbox’ içerisinde bulunan DVM algoritmasının gerçeklendiği fonksiyon kullanılmıştır. Bu fonksiyonun parametreleri değiştirilerek özelleştirilebilmektedir. Bu çalışmada parametreler değiştirilerek veri her özelliğin ortalaması temel alınarak standartlaştırılmış ve algoritmanın çalışması sağlanmıştır. Çalışmada bulunan veriler 38 ayrı kişiye ait olduğu için, 2’den fazla sınıf kategorisi bulunmaktadır. Bu sebeple çoklu sınıflandırmaya uygun olarak destek vektör makineleri fonksiyonu kullanılmıştır.
KYK yöntemi ise uzaklık ölçümüne dayalı çalışan bir gözetimli öğrenme yöntemidir. Başlangıçta rastgele belirlenen merkezler etrafında toplanan verilerin en yakın merkezin bulunduğu sınıfa dahil edilmesi ile gerçekleştirilen sınıflandırma yöntemidir. Birkaç deneme ile uygun merkezler ve dağılımlar elde edilir. Algoritma sınıflandırılmak istenen verinin sınıfına en yakın verinin sınıfına bakılarak karar verdiği gibi, tercihe göre en yakın N adet komşuya bakarak da karar verebilir. MATLAB 2019b’de bulunan algoritma, varsayılan olarak en yakın 1 komşuya bakarak karar vermekte ancak tercihe göre bu sayı ve diğer metrikler değiştirilebilmektedir. Bu çalışmada en yakın 3 komşuya bakılarak karar verilmiş ve veri otomatik olarak DVM yönteminde olduğu gibi standartlaştırılmıştır. DVM algoritmasında test setinden yanlış sınıflandırılmış ve olması gereken sınıfa ait görüntü Şekil 3 ‘de örnek olarak gösterilmiştir.

a) Eşleştirilmek istenen görüntü
b) DVM yöntemi ile yanlış eşleştirilen görüntü
c) Eşleştirilmesi gereken doğru görüntü
b) Yapay Sinir Ağları ve Derin Öğrenme
Yapay sinir ağları ve derin öğrenme yöntemleri veri ön işleme aşamasına gerek kalmadan çalışma özellikleri ile bilinmektedirler. Son zamanlarda birçok alanda tercih edilen bu yöntemler, özellikle yüksek sınıflandırma başarısı sebebi ile tercih edilmektedir.
Yapay sinir ağları için MATLAB’ın “Neural Network Pattern Recognition” uygulaması kullanılmıştır. Uygulamanın ara yüzü kullanılarak ağ için gerekli girdi setinin ve sınıf değişkeninin bulunduğu vektörün çalışma alanından seçildiği, eğitim, onay ve test setlerinin yüzdelik olarak ayrılması Şekil 4’de gösterilmektedir.


veri seti seçilmesi, eğitim ve test setlerinin belirlenmesi
Ağ için 1729 adet fotoğraf modelin eğitilmesi için 370 adet fotoğraf onaylanması ve 370 fotoğraf test edilmesi için kullanılmıştır. Ağda bulunan gizli katman sayısı, arayüz üzerinden ayarlanabilir olup bu çalışma için 10 seçilmiştir. Şekil 5’de bu çalışma için tasarlanan ağ yapısı gösterilmiştir. Her bir fotoğraf 192×168 boyutlarındadır ve sınıflandırma için 32256 adet özellik/girdi ile temsil edilmektedir. Veri setinde 38 farklı kişiye ait fotoğraf olduğundan sınıflandırılması gereken kategori sayısı ve ağın çıktı sayısı 38 olarak belirlenmiştir.

veri seti seçilmesi, eğitim ve test setlerinin belirlenmesi
Derin öğrenme yöntemi için MATLAB kullanılarak tasarlanan katmanlar ve bu ağ için belirlenen ayarlamalar ile ilgili örnek Şekil 6’de gösterilmiş ve ilgili parametrelerde aşağıda anlatıldığı gibi değişiklikler yapılmıştır. Derin öğrenmede öğrenme, optimizasyon algoritmaları üzerinden gerçekleşmektedir. Literatürde optimizasyon algoritması için genellikle ‘Stochastic Gradient Descent (SGD)’ yöntemi kullanılmaktadır. Ancak bu yöntemin yavaş çalışıyor olması görüntü işleme gibi yüksek boyutta veriler için önerilmemekte ve sınıflandırma başarısı da düşmektedir. Bu algoritmaya alternatif olarak ‘Adam’ algoritması önerilmektedir. Algoritma sistemin öğrenme hızını her hata hesaplamasında güncelleyerek kendi kendine güncelleme/öğrenme özelliğine sahiptir. Başlangıçta belirlenen öğrenme hızı parametre değeri algoritma tarafından belirlenen sonraki öğrenme hızı değerlerini etkilemektedir. Çalışmamızda derin öğrenme için tasarlanan sistem SGD ve Adam algoritmaları ve iki farklı öğrenme katsayısı değeriyle 4 kez tekrarlanmıştır.
layers = [
imageInputLayer([224 224 1])
convolution2dLayer(3,8,’Padding’,’same’)
batchNormalizationLayer
reluLayer
maxPooling2dLayer(2,’Stride’,2)
convolution2dLayer(3,16,’Padding’,’same’)
batchNormalizationLayer
reluLayer
maxPooling2dLayer(2,’Stride’,2)
convolution2dLayer(3,32,’Padding’,’same’)
batchNormalizationLayer
reluLayer
fullyConnectedLayer(38)
softmaxLayer
classificationLayer];
options = trainingOptions(‘adam’, …
‘GradientDecayFactor’ ,0.9,…
‘InitialLearnRate’,0.002, …
‘MaxEpochs’,4,…
‘ExecutionEnvironment’,’gpu’,…
‘Shuffle’,’every-epoch’, …
‘ValidationData’,imdsValidation, …
‘ValidationFrequency’,30, …
‘Verbose’,false, …
‘Plots’,’training-progress’);
Şekil 6 Çalışmada kullanılan derin öğrenme mimarisi ve
parametrelerden örnek
Derin öğrenme için her sınıf etiketine ait 45 görüntü eğtitim setine, 20 görüntü test setine ayrılarak toplamda eğitim için 1755, test için 780 görüntü kullanılmıştır.
SONUÇLAR
Çalışmada kullanılan algoritmalardan DVM ve KYK yöntemleri orijinal görüntüler ve temel bileşen analizi ile ¼ oranında boyutu azaltılmış temel bileşenlerden oluşan görüntü üzerinde uygulanmıştır. DVM yöntemi için boyutu azaltılmış verinin doğru tahmin oranında orijinal görüntüye göre 0.0016 oranında, KYK yönteminde ise 0.0147 oranında azalma görülmüştür. Algoritmaların doğruluk oranlarına Şekil 6.’da yer verilmiştir.

algoritmalarının orijinal ve temel bileşen analizi (tba) sonrası
veriler ile doğru tahmin oranları (%)
Şekil 7’de gösterildiği gibi doğruluk oranlarında temel bileşen analizinden sonra çok büyük bir fark olmamak ile birlikte hafızada kapladıkları yer açısından büyük oranda tasarruf sağlanmaktadır. Bu sebeple temel bileşen analizi büyük veriler için tercih edilebilir görülmektedir. Bununla birlikte verileri kullanarak eğitim ve test için gerekli sürelerde temel bileşen analizinden sonra dikkat çekici azalma görülmektedir.

Şekil 8.’de görüldüğü gibi özelikle KYK algoritmasında temel bileşen analizinden sonra modelin eğitimi ve testi için gerekli süre 21.072 saniye azalmıştır. DVM algoritması için ise gerekli süre 6.292 saniye azalmıştır. Tasarruf edilen bellek ve zaman ölçütlerinin yanında ortaya çıkan doğruluk oranındaki azalma ise sistem gereksinimlerine göre tolere edilebilecek seviyede gözükmektedir.
Yapay sinir ağları bu veri setinde %88.4 oranında doğru tahminde bulunmuştur. Ağın eğitilmesi ve test edilmesi ise 1 dakika 48 saniye sürmüştür. Ağ ile detaylı bilgi uygulamanın Şekil 9’da gösterilen arayüzü üzerinden görülebilmektedir.
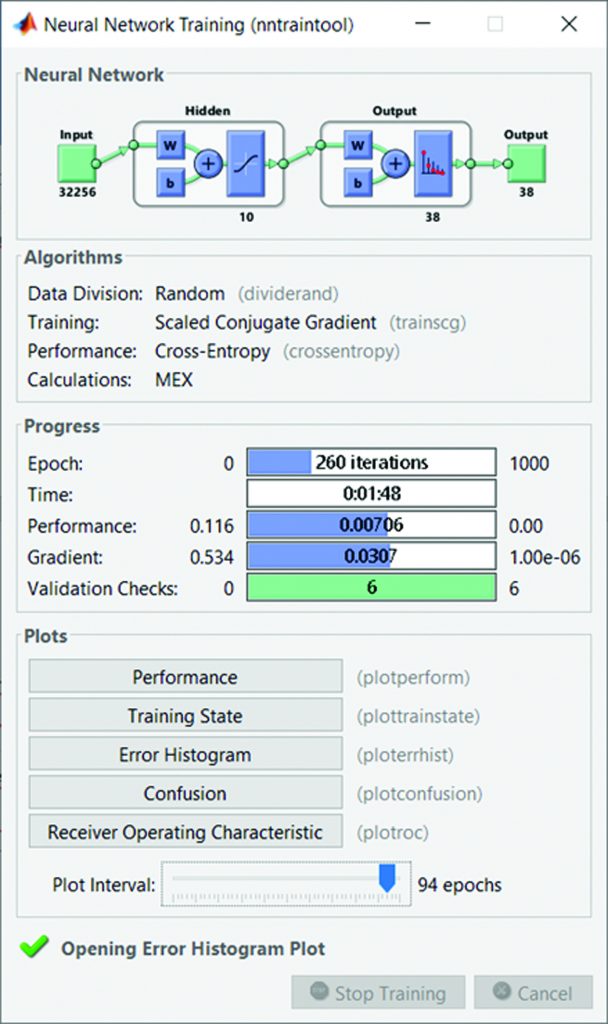
Network Uygulama arayüzündeki performans sonuçları
Derin öğrenmede ise öğrenme hızını 0.001 ve 0.002 değerleri ile değiştirerek performans karşılaştırması yapılmıştır. Ayrıca optimizasyon algoritmasını da değiştirerek SGM ve ADAM yöntemleri karşılaştırılmıştır. Şekil 10’ da görüldüğü gibi en iyi sonucu derin öğrenme algoritmalarından ADAM optimizasyon algoritması 0.001 başlangıç öğrenme hızı(k) parametresiyle 95.01% doğru tahmin oranı ile göstermiştir.

ADAM) Doğru Tahmin Başarısı
Çalışmamızda doğru tahmin açısından en başarılı sonucu 95.01% oranı ile derin öğrenme 75.68% oranı ile k-en yakın komşu algoritması vermiştir. Derin öğrenme modelinin eğitimi sırasında oluşan doğruluk ve kayıp oranlarını gösteren ayrıntılı grafik ise Şekil 12 verilmektedir. Yapay sinir ağları ise eğitim ve test için gereken süre açısından değerlendirildiğinde 108 saniye ile en yavaş algoritma olarak analiz edilmiştir.
KAYNAKÇA
Yale Face Database. (2020). UCSD Computer Vision: http://vision.ucsd.edu/content/yale-face-database adresinden alındı
