Pekiştirmeli Öğrenme Nedir?
Pekiştirmeli öğrenme, bir bilgisayar aracısının dinamik bir ortamla tekrarlanan deneme yanılma etkileşimleri yoluyla bir görevi gerçekleştirmeyi öğrendiği bir tür makine öğrenimi tekniğidir. Bu öğrenme yaklaşımı, aracının, insan müdahalesi olmadan ve görevi başarmak için açıkça programlanmadan, görev için bir ödül ölçütünü maksimuma çıkaran bir dizi karar vermesini sağlar.
Pekiştirmeli öğrenme ile eğitilen yapay zeka programları, video oyunlarının yanı sıra Go ve satranç gibi masa oyunlarında insan oyuncuları yener. Pekiştirmeli öğrenme kesinlikle yeni bir kavram olmasa da, derin öğrenme ve bilgi işlem gücündeki son gelişmeler, yapay zeka alanında bazı dikkate değer sonuçlar elde etmeye olanak tanıdı.
-
Neden Önemlidir?
-
Nasıl çalışır?
-
MATLAB ve Simulink ile Pekiştirmeli Öğrenme
Pekiştirmeli Öğrenme Neden Önemlidir?
Pekiştirmeli Öğrenme, Makine Öğrenmesi ve Derin Öğrenme
Pekiştirmeli öğrenme, makine öğrenmesinin bir dalıdır (Şekil 1). Gözetimsiz ve gözetimli makine öğrenmesinden farklı olarak, Pekiştirmeli öğrenme statik bir veri kümesine dayanmaz, dinamik bir ortamda çalışır ve toplanan deneyimlerden öğrenir. Veri noktaları veya deneyimler, eğitim sırasında ortam ve bir yazılım aracısı arasındaki deneme-yanılma etkileşimleri yoluyla toplanır. Pekiştirmeli öğrenmenin bu yönü önemlidir, çünkü eğitimden önce veri toplama, ön işleme ve etiketleme ihtiyacını azaltır, aksi halde gözetimli ve gözetimsiz öğrenmede gerekli olur. Pratik olarak bu, doğru teşvik verildiğinde, bir Pekiştirmeli öğrenme modelinin (insan) gözetimi olmadan kendi başına bir davranışı öğrenmeye başlayabileceği anlamına gelir.
Derin öğrenme, makine öğrenmesi üç türünü de kapsar; Pekiştirmeli öğrenme ve derin öğrenme birbirini dışlamaz. Karmaşık Pekiştirmeli öğrenme problemleri genellikle derin Pekiştirmeli öğrenme olarak bilinen bir alan olan derin sinir ağlarına dayanır.
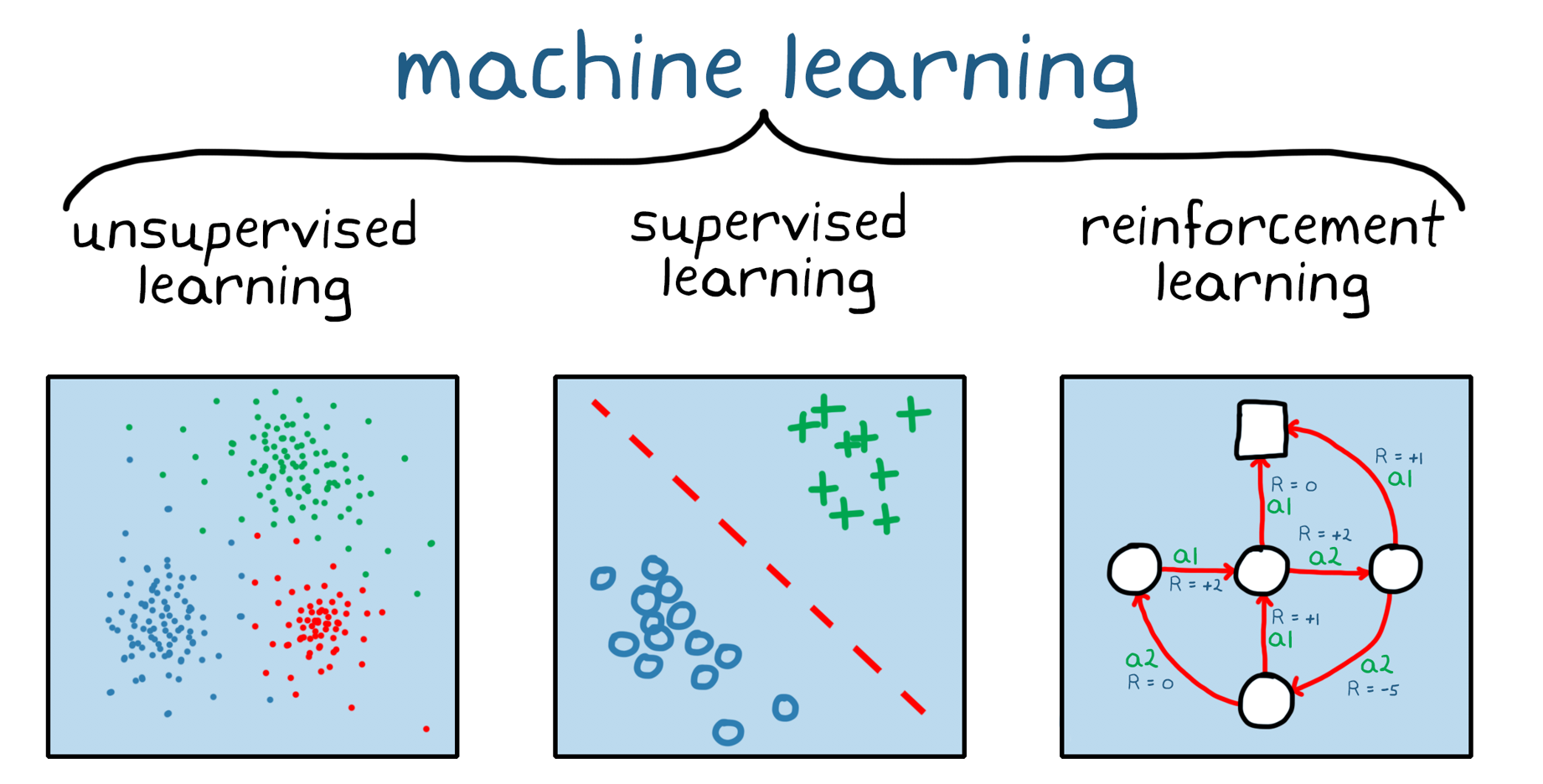
Şekil 1. Üç geniş makine öğrenmesi kategorisi: gözetimsiz öğrenme, gözetimli öğrenme ve Pekiştirmeli öğrenme.
Pekiştirmeli Öğrenme (7 Video)
MATLAB ve Simulink ile Pekiştirmeli Öğrenme
Pekiştirmeli Öğrenme Uygulamalarından Örnekler
Pekiştirmeli öğrenme ile eğitilen derin sinir ağları, karmaşık davranışları kodlayabilir. Bu, normalde zor olan veya geleneksel yöntemlerle üstesinden gelinmesi daha zor olan uygulamalara alternatif bir yaklaşım sağlar. Örneğin otonom sürüşte, bir sinir ağı sürücünün yerini alabilir ve kamera çerçeveleri ve lidar ölçümleri gibi birden fazla sensöre aynı anda bakarak direksiyon simidinin nasıl döndürüleceğine karar verebilir. Sinir ağları olmadan, sorun normalde kamera çerçevelerinden özelliklerin çıkarılması, lidar ölçümlerinin filtrelenmesi, sensör çıktılarının birleştirilmesi ve sensör girdilerine dayalı olarak “sürüş” kararlarının verilmesi gibi daha küçük parçalara bölünürdü.
Bir yaklaşım olarak Pekiştirmeli öğrenme, üretim sistemleri için hâlâ değerlendirme aşamasındayken, bazı endüstriyel uygulamalar bu teknoloji için iyi adaylardır.
Gelişmiş kontroller: Doğrusal olmayan sistemleri kontrol etmek, genellikle sistemi farklı çalışma noktalarında doğrusallaştırarak ele alınan zorlu bir problemdir. Pekiştirmeli öğrenme doğrudan doğrusal olmayan sisteme uygulanabilir.
Otomatik sürüş: Görüntü uygulamalarında derin sinir ağlarının başarısı göz önüne alındığında, kamera girdisine dayalı sürüş kararları vermek, Pekiştirmeli öğrenmenin uygun olduğu bir alandır.
Robotik: Pekiştirmeli öğrenme, bir robot koluna çeşitli nesneleri alıp yerleştir uygulamaları için nasıl manipüle edeceğini öğretmek gibi robotik kavrama gibi uygulamalarda yardımcı olabilir. Diğer robot uygulamaları, insan-robot ve robot-robot işbirliğini içerir.
Zamanlama: Zamanlama sorunları, trafik ışığı kontrolü ve fabrika katındaki kaynakları bir hedefe doğru koordine etme dahil olmak üzere birçok senaryoda ortaya çıkar. Pekiştirmeli öğrenme, bu birleşimsel optimizasyon problemlerini çözmek için evrimsel yöntemlere iyi bir alternatiftir.
Ayarlama: Elektronik kontrol ünitesi (ECU) ayarlaması gibi parametrelerin manuel ayarlamasını içeren uygulamalar, takviye öğrenme için iyi adaylar olabilir.
Pekiştirmeli Öğrenme Nasıl Çalışır?
Pekiştirmeli öğrenmenin arkasındaki eğitim mekanizması, birçok gerçek dünya senaryosunu yansıtır. Örneğin, olumlu pekiştirme yoluyla evcil hayvan eğitimini düşünün.
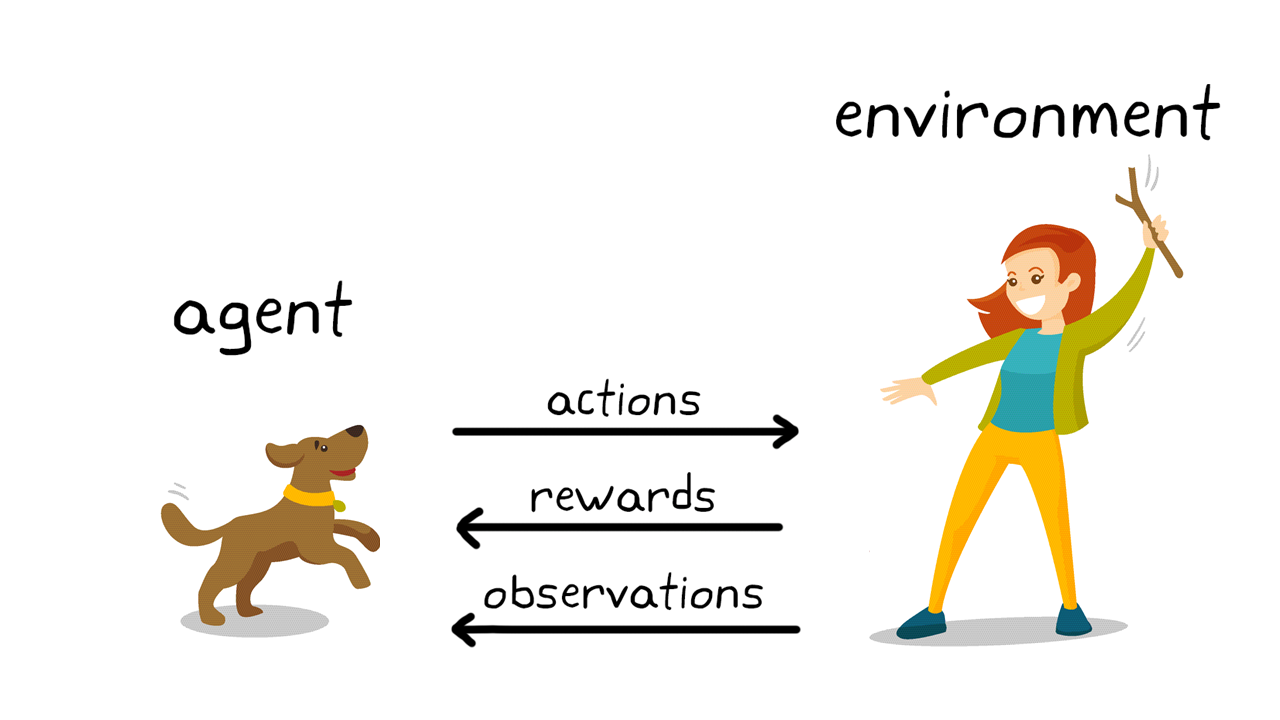
Şekil 2. Köpek eğitiminde Pekiştirmeli öğrenme.
Pekiştirmeli öğrenme terminolojisini kullanarak (Şekil 2), bu durumda öğrenmenin amacı, köpeği (ajan) hem köpeğin hem de eğiticinin çevresini içeren bir ortamda bir görevi tamamlaması için eğitmektir. İlk olarak, eğitmen, köpeğin gözlemlediği (gözlem) bir komut veya işaret verir. Köpek daha sonra bir eylemde bulunarak yanıt verir. Eylem, istenen davranışa yakınsa, eğitmen muhtemelen bir yiyecek ikramı veya oyuncak gibi bir ödül verecektir; aksi halde ödül verilmeyecektir. Eğitimin başlangıcında, belirli gözlemleri eylemler ve ödüllerle ilişkilendirmeye çalıştığı için, verilen komut “otur” olduğunda, köpek muhtemelen yuvarlanmak gibi daha rastgele eylemler gerçekleştirecektir. Gözlemler ve eylemler arasındaki bu ilişkilendirme veya haritalama, ilke olarak adlandırılır. Köpeğin bakış açısına göre, ideal durum, köpeğin mümkün olduğu kadar çok ödül alması için her işarete doğru tepki vermesidir. Bu nedenle, Pekiştirmeli öğrenme eğitiminin tüm anlamı, köpeğin politikasını, ödülü en üst düzeye çıkaracak istenen davranışları öğrenmesi için “ayarlamaktır”. Eğitim tamamlandıktan sonra köpek, sahibini gözlemleyebilmeli ve geliştirdiği iç politikayı kullanarak “otur” komutu verildiğinde oturmak gibi uygun eylemi gerçekleştirebilmelidir. Bu noktada, ikramlar kabul edilir ancak teorik olarak gerekli olmamalıdır.
Köpek eğitimi örneğini akılda tutarak, bir aracı otomatik sürüş sistemi kullanarak park etme görevini düşünün (Şekil 3). Amaç, Pekiştirmeli öğrenme ile araç bilgisayarına (temsil) doğru park yerine park etmesini öğretmektir. Köpek eğitimi örneğinde olduğu gibi, çevre aracının dışındaki her şeydir ve aracın dinamiklerini, yakınlarda olabilecek diğer araçları, hava koşullarını vb. içerebilir. Eğitim sırasında aracı, yönlendirme, frenleme ve hızlanma komutları (eylemler) oluşturmak için kameralar, GPS ve lidar (gözlemler) gibi sensörlerden gelen okumaları kullanır. Aracı, gözlemlerden doğru eylemlerin nasıl üretileceğini öğrenmek için (politika ayarı), deneme yanılma sürecini kullanarak aracı tekrar tekrar park etmeye çalışır. Bir denemenin iyiliğini değerlendirmek ve öğrenme sürecini yönlendirmek için bir ödül sinyali sağlanabilir.
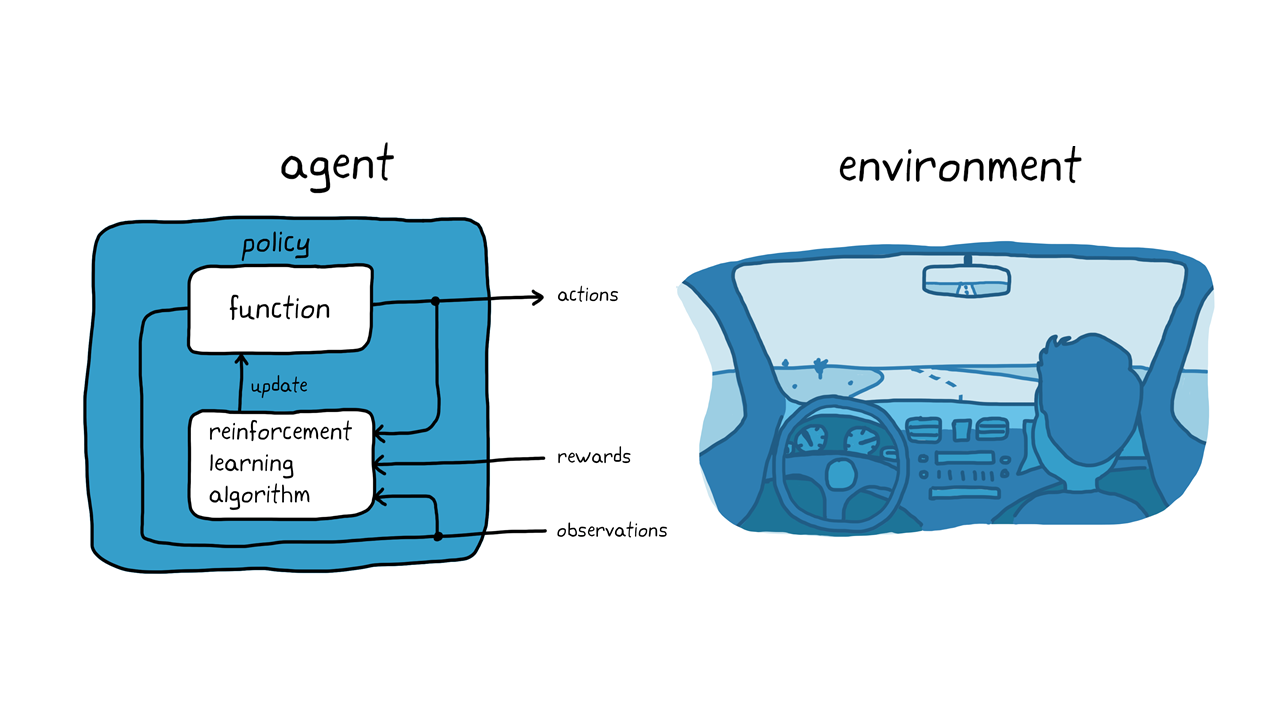
Şekil 3. Otonom parkta Pekiştirmeli öğrenme.
Köpek eğitimi örneğinde, eğitim köpeğin beyninin içinde gerçekleşmektedir. Otonom park etme örneğinde, eğitim bir eğitim algoritması tarafından gerçekleştirilir. Eğitim algoritması, aracının politikasını toplanan sensör okumalarına, eylemlerine ve ödüllerine göre ayarlamaktan sorumludur. Eğitim tamamlandıktan sonra, aracın bilgisayarı yalnızca ayarlanan ilkeyi ve sensör okumalarını kullanarak park edebilmelidir.
Akılda tutulması gereken bir şey, Pekiştirmeli öğrenmenin örnekleme açısından verimli olmadığıdır. Yani, eğitim için veri toplamak üzere etmen ile çevre arasında çok sayıda etkileşim gerektirir. Örneğin, Go oyununda bir dünya şampiyonunu yenen ilk bilgisayar programı olan AlphaGo, milyonlarca oyun oynayarak, binlerce yıllık insan bilgisini biriktirerek birkaç gün boyunca aralıksız eğitildi. Nispeten basit uygulamalar için bile, eğitim süresi dakikalardan saatlere veya günlere kadar sürebilir. Ayrıca, doğru olması için birkaç yineleme gerektirebilecek, verilmesi gereken tasarım kararlarının bir listesi olduğundan, sorunu doğru bir şekilde kurmak zor olabilir. Bunlar, örneğin sinir ağları için uygun mimarinin seçilmesini, hiperparametrelerin ayarlanmasını ve ödül sinyalinin şekillendirilmesini içerir.
Pekiştirmeli Öğrenme İş Akışı
Pekiştirmeli öğrenmeyi kullanarak bir aracıyı eğitmek için genel iş akışı aşağıdaki adımları içerir (Şekil 4):

Şekil 4. Pekiştirmeli öğrenme iş akışı.
1. Ortamı oluşturun
Öncelikle, etmen ile ortam arasındaki arayüz de dahil olmak üzere, Pekiştirmeli öğrenme aracısının içinde çalıştığı ortamı tanımlamanız gerekir. Ortam, bir simülasyon modeli veya gerçek bir fiziksel sistem olabilir, ancak simüle edilmiş ortamlar genellikle daha güvenli oldukları ve deney yapmaya izin verdikleri için iyi bir ilk adımdır.
2. Ödülü tanımlayın
Ardından, aracının görev hedeflerine göre performansını ölçmek için kullandığı ödül sinyalini ve bu sinyalin ortamdan nasıl hesaplandığını belirtin. Ödül şekillendirme zor olabilir ve doğru olması için birkaç yineleme gerektirebilir.
3. Temsil oluşturun
Ardından, politika ve Pekiştirmeli öğrenme eğitimi algoritmasından oluşan aracıyı yaratırsınız. Yani yapmanız gerekenler:
a) Politikayı temsil etmenin bir yolunu seçin (sinir ağları veya arama tabloları kullanmak gibi).
b) Uygun eğitim algoritmasını seçin. Farklı temsiller genellikle belirli eğitim algoritması kategorilerine bağlıdır. Ancak genel olarak, çoğu modern Pekiştirmeli öğrenme algoritması, büyük durum/eylem alanları ve karmaşık problemler için iyi adaylar oldukları için sinir ağlarına güvenir.
4. Temsili eğitin ve onaylayın
Eğitim seçeneklerini ayarlayın (durdurma kriterleri gibi) ve aracıyı politikayı ayarlaması için eğitin. Eğitim bittikten sonra eğitilen politikayı doğruladığınızdan emin olun. Gerekirse, ödül sinyali ve politika mimarisi gibi tasarım seçeneklerini yeniden gözden geçirin ve yeniden eğitin. Pekiştirmeli öğrenmenin genellikle örnek verimsiz olduğu bilinmektedir; eğitim, uygulamaya bağlı olarak dakikalardan günlere kadar sürebilir. Karmaşık uygulamalar için birden çok CPU, GPU ve bilgisayar kümesi üzerinde eğitimi paralel hale getirmek işleri hızlandırır (Şekil 5).
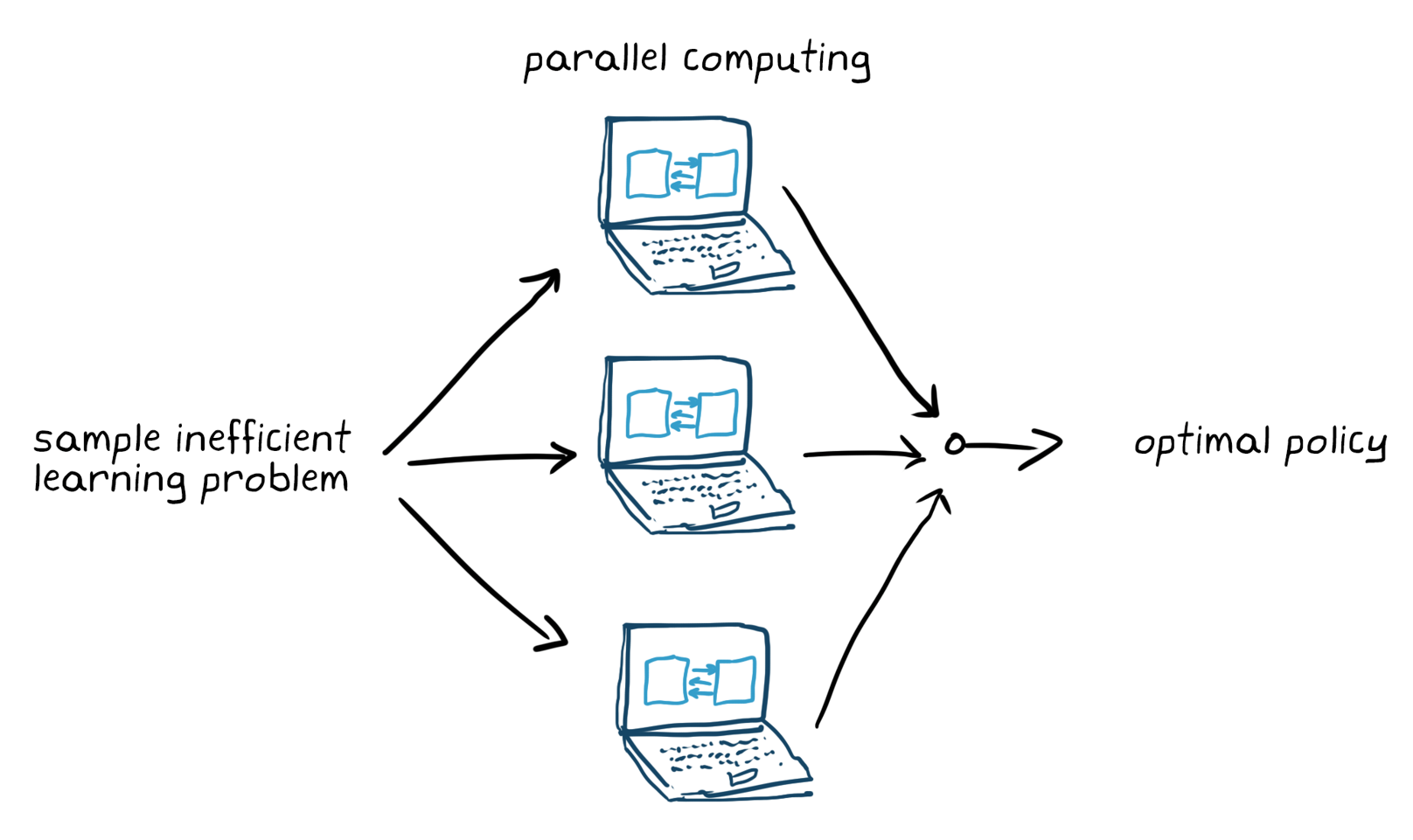
Şekil 5. Paralel bilgi işlem ile verimsiz öğrenme probleminin eğitim örneği.
5. Politikayı dağıtın
Örneğin, oluşturulmuş C/C++ veya CUDA kodunu kullanarak eğitimli politika temsilini dağıtın. Bu noktada, politika bağımsız bir karar alma sistemidir.
Pekiştirmeli öğrenmeyi kullanarak bir temsilciyi eğitmek yinelemeli bir süreçtir. Daha sonraki aşamalardaki kararlar ve sonuçlar, öğrenme iş akışında daha önceki bir aşamaya dönmenizi gerektirebilir. Örneğin, eğitim süreci makul bir süre içinde optimal bir politikaya yakınsamıyorsa aracıyı yeniden eğitmeden önce aşağıdakilerden herhangi birini güncellemeniz gerekebilir:
• Eğitim ayarları
• Pekiştirmeli öğrenme algoritma yapılandırması
• Politika temsili
• Ödül sinyali tanımı
• Eylem ve gözlem sinyalleri
• Çevre dinamikleri
MATLAB ve Simulink ile Pekiştirmeli Öğrenme
MATLAB® ve Reinforcement Learning Toolbox™, Pekiştirmeli öğrenme görevlerini basit hale getirir. Pekiştirmeli öğrenme iş akışının her adımında çalışarak, robotlar ve otonom sistemler gibi karmaşık sistemler için kontrolcüler ve karar alma algoritmaları uygulayabilirsiniz. Özellikle şunları yapabilirsiniz:
1. MATLAB ve Simulink® kullanarak ortamlar oluşturun ve işlevleri ödüllendirin
2. Pekiştirmeli öğrenme politikalarını tanımlamak için derin sinir ağlarını, polinomları ve arama tablolarını kullanın
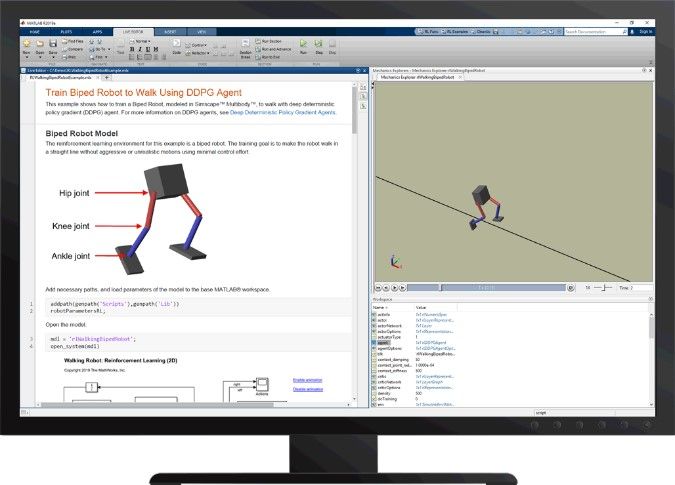
Şekil 6 İki ayaklı bir robota Reinforcement Learning Toolbox™ ile yürümeyi öğretme
3. DQN, DDPG, PPO ve SAC gibi popüler Pekiştirmeli öğrenme algoritmalarını yalnızca küçük kod değişiklikleriyle değiştirin, değerlendirin ve karşılaştırın veya kendi özel algoritmanızı oluşturun
4. Birden çok GPU’dan, birden çok CPU’dan, bilgisayar kümesinden ve bulut kaynaklarından yararlanarak Pekiştirmeli öğrenme politikalarını daha hızlı eğitmek için Parallel Computing Toolbox™ ve MATLAB Parallel Server™ kullanın
5. MATLAB Coder™ ve GPU Coder™ ile gömülü cihazlara kod oluşturun ve Pekiştirmeli öğrenme politikalarını dağıtın
6. Referans örnekleri kullanarak Pekiştirmeli öğrenmeye başlayın.
İlgili ürünler: Reinforcement Learning Toolbox™, Deep Learning Toolbox™, Parallel Computing Toolbox™, MATLAB Parallel Server, GPU Coder, MATLAB Coder, Simscape™