Sistem hedeflerini karşılamak için kontrol teknikleri tasarlamak ve uygulamak
Optimal kontrol, tasarım hedeflerini karşılayan dinamik sistemlerin koşuludur. Optimal kontrol, aşağıdaki tanımlanmış optimallik kriterlerini yürüten kontrol kuralları ile sağlanır. Yaygın olarak kullanılan bazı optimal kontrol teknikleri şunlardır:Bir güç dönüştürücü tasarlarken, aşağıdaki görevleri yerine getirmek için simülasyonu göz önünde bulundurmalısınız:
- Lineer Kuadratik Regülator (LQR)/Lineer Kuadratik Gauss (LQG) kontrolü
- Model Öngörülü Kontrol
- Takviyeli Öğrenme
- Aşırılık Arayan Kontrol
- H-Sonsuz sentezi
Lineer Kuadratik Regülatör (LQR)/Lineer Kuadratik Regülatör Gauss (LQG) kontrolü
Lineer Kuadratik Regülatör (LQR), kontrol sistemini düzenlemek için kuadratik bir maliyet fonksiyonunu en aza indiren tam durum geri beslemeli optimal kontrol kuralıdır.
u=−Kxu=−Kx.
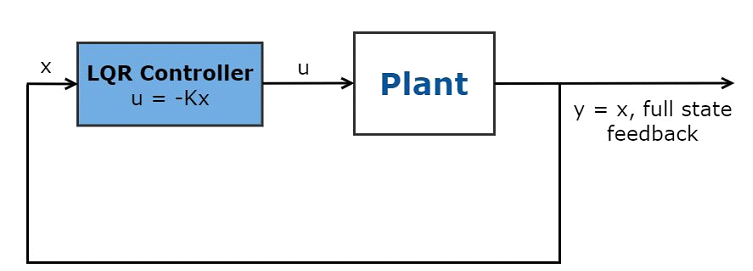
Şekil 1. Lineer Kuadratik Regülatör kontrolcüsünün şeması.
Bu maliyet fonksiyonu, aşağıda gösterildiği gibi sistem durumlarına (x) ve kontrol girişlerine (u) bağlıdır.
![]()
Performans özelliklerine bağlı olarak, sistem durumu düzenlemesi ile kontrol etkinleştirme maliyeti arasındaki uygun dengeyi tanımlamak için bu optimum kontrol kuralının Q, R ve N ağırlıklandırma faktörleri ayarlanır.
Pek çok optimal kontrol probleminde tüm durum ölçümlerine erişilemez. Bu durumlarda, durumlar bir gözlemci kullanılarak tahmin edilmelidir. Bu genellikle Kalman filtresi gibi bir gözlemci kullanılarak yapılır. Bir LQR kontrolcüsü ile birleştirilmiş bir Kalman filtresi, bir Lineer Kuadratik Gauss (LQG) kontrolcüsü oluşturur.

Şekil 2. Lineer Kuadratik Gauss kontrolcüsünün şeması.
Daha fazlasını öğrenmek için, LQR kontrolünde MATLAB tech talk (17:23) videosuna göz atın.
Model Öngörülü Kontrol
Model Öngörülü Kontrol (MPC), girdi ve çıktı kısıtlamalarına tabi olan çok girdili çok çıktılı (MIMO) sistemlerde bir maliyet işlevini en aza indirmek için kullanılır. Bu optimal kontrol tekniği, gelecekteki sistem modeli çıktılarını tahmin etmek için bir sistem modeli kullanır. Kontrolcü, tahmin edilen sistem modelinin çıktılarını kullanarak, tahmin edilen çıktıyı referansa yönlendiren manipüle edilebilir bir değişkene yönelik optimum ayarlamaları belirlemek için kuadratik bir program olan çevrimiçi bir optimizasyon problemini çözer. MPC varyantları, uyarlanabilir, kazanç programlı ve doğrusal olmayan MPC kontrolcülerini içerir. Kullanılan MPC kontrolcüsünün türü, tahmin modeline (doğrusal/doğrusal olmayan), kısıtlamalara (doğrusal/doğrusal olmayan), maliyet fonksiyonuna (kuadratik/kuadratik olmayan), iş hacmine ve örnekleme süresine bağlıdır.

Şekil 3. Model Öngörülü Kontrolün Şeması.
Mikroişlemci teknolojisindeki gelişmeler ve verimli algoritmalar, otomatik sürüş, havacılık uygulamalarında optimum arazi takibi vb. uygulamalarda bu optimum kontrol yönteminin benimsenmesini artırmıştır.
Takviyeli Öğrenme
Takviyeli öğrenme, bir bilgisayar aracısının dinamik bir ortamla tekrarlanan deneme yanılma etkileşimleri yoluyla en uygun davranışı öğrendiği bir makine öğrenme tekniğidir. Aracı, görev için aracının kümülatif ödül ölçüsünü en üst düzeye çıkarmak amacıyla bir dizi eylemi gerçekleştirmek için çevreden gözlemleri kullanır. Bu öğrenme, insan müdahalesi olmadan ve açık programlama olmadan gerçekleşir.
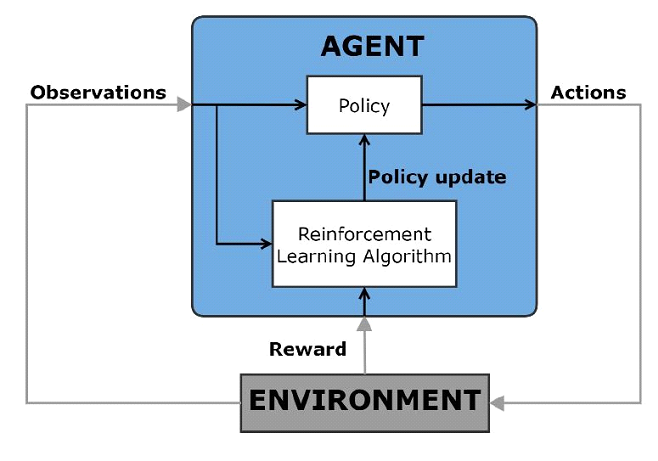
Şekil 4. Takviyeli Öğrenme Şeması.
Bu optimal kontrol yöntemi, karar verme problemlerinde ve otomatik sürüş, robotik, çizelgeleme problemleri ve sistemlerin dinamik kalibrasyonu gibi geleneksel kontrol yöntemlerini kullanan uygulamalarda doğrusal olmayan bir kontrol alternatifi olarak kullanılabilir.
Ekstremum Arama Kontrolü
Ekstremum arama, modelden bağımsız gerçek zamanlı optimizasyon kullanarak bir amaç işlevini en üst düzeye çıkarmak için kontrol sistemi parametrelerini otomatik olarak uyarlayan bir optimal kontrol tekniğidir. Bu yöntem, bir sistem modeli gerektirmez ve parametrelerin ve bozulmaların zaman içinde yavaşça değiştiği sistemler için kullanılabilir. Bu optimal kontrol tekniği, kontrolde gürültüyü tolere edebilen ve sadece az sayıda kontrol sistemi parametresinin uyarlanması gereken kararlı sistemler için uygundur.
Ekstremum arama kontrolün uygulamaları arasında uyarlanabilir hız sabitleyici, güneş panelleri için maksimum güç noktası takibi (MPPT) ve kilitlenmeyen fren sistemleri (ABS) bulunur.
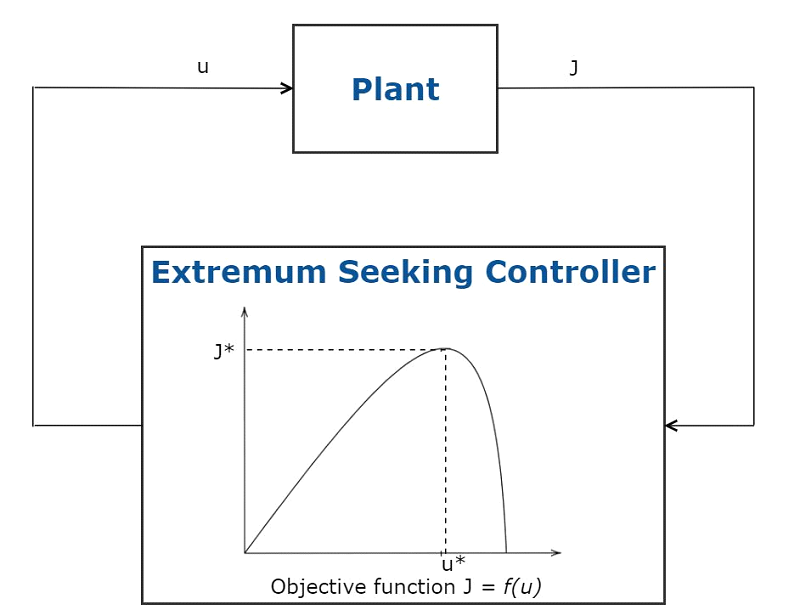
Şekil 5. Extremum Arama Kontrolün Şeması.
H-Sonsuz Sentezi
H-sonsuz sentezi, sağlam performans ve kararlılık elde etmek için tek girişli tek çıkışlı (SISO) veya MIMO geri besleme kontrolcülerini tasarlamak için en uygun kontrol aracı/tekniğidir. Bode ile döngü şekillendirme veya PID ayarlama gibi klasik kontrol teknikleriyle karşılaştırıldığında H-Sonsuz, kanallar arasında çapraz bağlantı gerektiren çok değişkenli kontrol sistemleri için daha uygundur.
H-sonsuz ile kontrol hedefleri, normalleştirilmiş kapalı döngü kazancı açısından formüle edilir. H-sonsuz sentezi, bu kazancı en aza indirerek performansı optimize eden bir kontrolcü otomatik olarak hesaplar. Bu yararlıdır, çünkü birçok kontrol hedefi kazançları en aza indirme açısından ifade edilebilir. Bu, bozulma reddi, gürültüye duyarlılık, izleme, döngü şekillendirme, döngü ayrıştırma ve sağlam kararlılık gibi hedefleri içerir. H-sonsuz sentezinin varyasyonları, hem sabit yapılı hem de tam sıralı kontrolcüleri işlemek için kullanılabilir.
Aşağıdaki tablo, yukarıda açıklanan optimum kontrol yöntemlerini karşılaştırır:
|
Optimum Kontrol Yöntemi |
Optimizasyon çalışma zamanında mı yapılıyor? (Evet Hayır) |
Optimizasyon süreci bu optimal kontrol süreci için nasıl çalışır? |
Zor kısıtlamaların üstesinden gelebilir mi?* (Evet/Hayır) |
Model tabanlı teknik kullanıyor mu? (Evet Hayır) |
İş/Zaman Oranı nedir? (Yüksek/Düşük) |
|
LQR/LQG |
Hayır |
Bilinen doğrusal zamanla değişmeyen sistemlerle çalışan kapalı form çözümü kullanır |
Hayır |
Evet |
Yüksek |
|
|
Bir tahmin modeli kullanarak, optimum kontrol eylemlerini hesaplamak için çevrimiçi bir optimizasyon problemini çözer |
Evet |
Evet |
Düşük (doğrusal olmayan MPC), Yüksek (doğrusal MPC) |
|
|
Açık Model Öngörülü Kontrol (MPC) (Hayır) |
Optimum kontrol eylemlerinin hesaplanması için optimizasyon probleminin çözümü çevrimdışı olarak hesaplanır |
Evet |
Evet |
Yüksek |
|
|
Takviyeli Öğrenme |
Evet** |
Ödül ölçümünü en üst düzeye çıkarmak için bir görev için en uygun davranışı öğrenir |
Hayır*** |
Eğitim algoritmasına bağlıdır |
Düşük (eğitim ile), Orta-Yüksek (çıkarım sırasında) |
|
Ekstremum Arama Kontrol |
Evet |
Bir amaç işlevini maksimum hale getirmek için kontrol parametrelerini sarsıma uğratır ve uyarlar |
Hayır |
Hayır |
Yüksek |
|
H-Sonsuz Sentez |
Hayır |
Normalleştirilmiş kapalı döngü kazancını en aza indiren bir kontrolcüyü otomatik olarak hesaplar |
Hayır |
Evet |
Yüksek |
* Kısıtlama zorlama bloğu ile kısıtlamalar uygulayabilirsiniz. Burada daha fazla bilgi edinin.
** Reinforcement Learning Toolbox™, ile aracıyı simüle edilmiş bir ortama karşı eğitebilirsiniz. Dağıtılan temsilci, çalışma zamanında güncellenmeyen eğitimli bir politikadır.
*** Politika yapısına göre eylem kısıtlamaları uygulayabilir ve ödül işlevleri aracılığıyla diğer kısıtlamaları teşvik edebilirsiniz