Simülasyon Sürelerini Nasıl Kısaltırsınız? Reduced Order Modeling Rehberi

Mühendislikte yüksek doğruluklu fizik tabanlı modeller çok değerlidir. Özellikle FEA, CFD veya PDE tabanlı modeller; sistem davranışını ayrıntılı biçimde temsil eder, tasarım kararlarını destekler ve fiziksel içgörü sağlar. Ancak aynı modelleri sistem seviyesi simülasyonlarda, kontrol tasarımında veya Hardware-in-the-Loop testlerinde kullanmak istediğimizde ciddi bir problem olan hesaplama maliyeti ile karşılaşırız.
Reduced Order Modeling (ROM), tam da bu noktada devreye girer. En basit haliyle ROM; bir modelin hesaplama karmaşıklığını azaltırken sistemin baskın davranışlarını korumayı amaçlayan yöntemler bütünüdür. Hedef, tam modeli birebir kopyalamak değil; kabul edilebilir doğrulukta ama çok daha hızlı çalışan bir temsil elde etmektir.
Bu yaklaşım sayesinde yüksek doğruluklu modeller, sistem seviyesinde yeniden kullanılabilir hale gelir. Böylece aynı fiziksel sistemi daha hafif, daha hızlı ve daha geniş test akışlarına uygun biçimde kullanmak mümkün olur.
Neden Reduced Order Modeling’e İhtiyaç Duyarız?
Yüksek doğruluklu mühendislik modellerinin en büyük avantajı ayrıntıdır; en büyük dezavantajı ise bu ayrıntının maliyetidir. Özellikle üçüncü parti FEA veya CFD araçlarından gelen modeller ya da PDE tabanlı çözümler, tek bir zaman adımında bile oldukça uzun çözüm sürelerine sahip olabilir.
Sistem seviyesi simülasyon, uzun süreli senaryo taraması, kontrol tasarımı ve HIL testleri gibi görevlerde bu maliyet çoğu zaman kabul edilemez hale gelir. Buradaki asıl mühendislik problemi, hızı artırırken doğruluk, güvenilirlik ve yorumlanabilirlik dengesini nasıl koruyacağımızdır.
İyi kurulmuş bir reduced-order model, yüksek doğruluklu modelin yerini tamamen almak zorunda değildir. Asıl değer, onu daha büyük mühendislik akışlarında kullanılabilir hale getirmesidir. ROM sayesinde simülasyon süreleri ciddi ölçüde düşürülebilir, daha fazla senaryo taranabilir ve fizik tabanlı modeller gerçek zamana yakın test ortamlarına taşınabilir.
ROM Yaklaşımı ve MATLAB&Simulink Ekosistemi
Reduced Order Modeling tek bir yöntem değildir. Farklı problem tipleri için farklı yaklaşımlar bulunur. Genel çerçevede ROM’u üç grupta düşünebiliriz: AI-based data-driven, linearization tabanlı ve model-based yöntemler.
Bu blog yazısının odağı özellikle AI-based data-driven ROM tarafıdır. Çünkü burada fiziksel sistemi her adımda tekrar çözmek yerine, yüksek doğruluklu modelden veya sistemden elde edilen giriş-çıkış verileriyle daha hafif bir model eğitilir. Başka bir deyişle, pahalı çözücüyü sürekli çalıştırmak yerine onun baskın davranışını öğrenen bir vekil model oluşturulur.
Bu yaklaşım özellikle elinizde güvenilir bir high-fidelity model varsa, o modeli farklı çalışma koşullarında koşturup veri üretebiliyorsanız ve hız kazanımı fiziksel ayrıntının tamamından daha kritik hale geldiyse oldukça güçlü bir seçenektir.
MathWorks ekosisteminin güçlü olduğu noktalardan birkaçı, veri hazırlama, model eğitimi, doğrulama, entegrasyon ve deploy adımlarını aynı ortamda bağlayabilmesidir. Bu açıdan ROM, tek başına duran bir kavram değil; daha geniş bir Model-Based Design ve AI mühendisliği hattının parçasıdır.
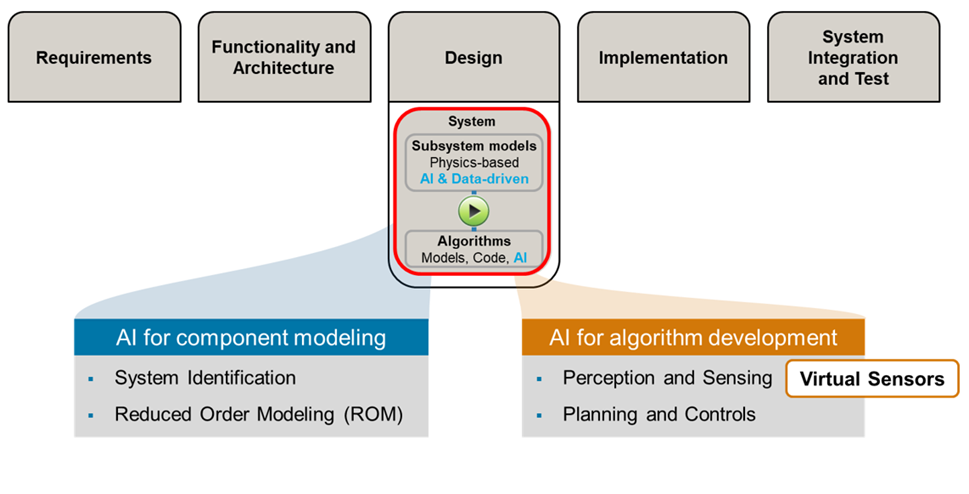
AI-based ROM akışında öne çıkan araçlar arasında Simulink, System Identification Toolbox, Statistics and Machine Learning Toolbox ve Deep Learning Toolbox yer alır. Bu akışta ROM geliştirme tarafında ise Reduced Order Modeler app kullanılır; uygulamanın kurulumu Reduced Order Modeler for MATLAB Support Package üzerinden yapılır. Doğrulama tarafında Deep Learning Toolbox Verification Library, deployment tarafında ise Code Generation ve hedef platform entegrasyonları önemli rol oynar.
Bu bütünlük sayesinde şu zincir kurulabilir: yüksek doğruluklu modelden veri üretmek veya mevcut veriyi içe almak, giriş ve çıkış sinyallerini seçmek, farklı ROM adaylarını eğitmek, modelleri karşılaştırmak, seçilen modeli Simulink’e entegre etmek ve sonrasında sistem seviyesinde doğrulayıp geliştirmek.
Örnek Problem: Jet Engine Turbine Blade Modelinin Hızlandırılması
ROM kavramı, somut bir kullanım senaryosu olmadan soyut kalabilir. Bu nedenle jet engine turbine blade örneği, yaklaşımı göstermek için oldukça açıklayıcıdır. Bu örnekte yüksek doğruluklu bir türbin kanadı modeli, yapay zeka tabanlı bir reduced-order model ile değiştirilir.
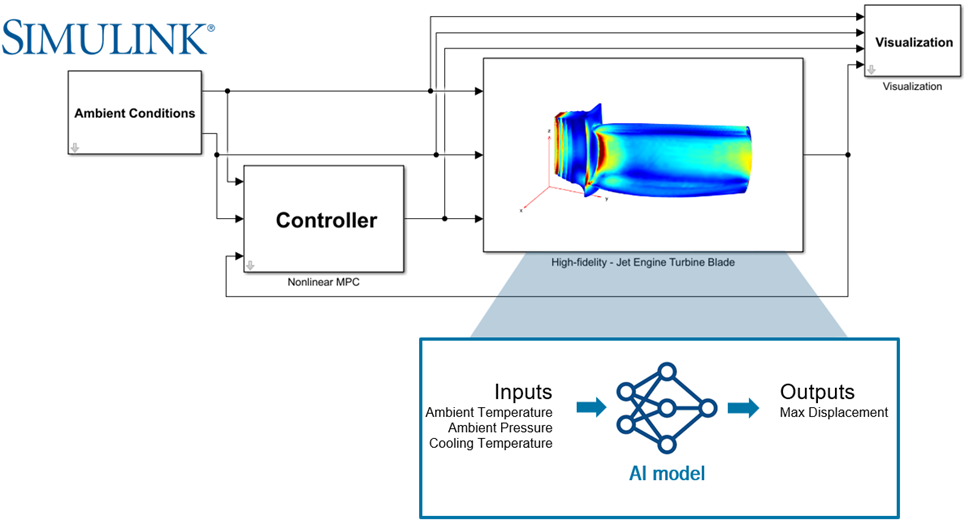
Sistemde girişler olarak ortam sıcaklığı, ortam basıncı ve soğutma sıcaklığı kullanılır. Çıktı ise maksimum yer değiştirmedir. Orijinal modelde türbin kanadının deformasyonu önce ısıl dağılımın hesaplanması, ardından yapısal denklemlerin çözülmesi ile elde edilir. Bu fiziksel olarak anlamlıdır; ancak simülasyon süresi yüksektir.
AI-based ROM burada aynı girişlerden benzer çıkışı çok daha hızlı tahmin etmeyi amaçlar. Böylece yüksek doğruluklu modelin fiziksel bilgisinden yararlanılırken, hesaplama yükü ciddi ölçüde azaltılır. Bu tür senaryolarda ROM’un değeri, yalnızca yaklaşık sonuç üretmesi değil; bu sonucu mühendislik kararlarını destekleyecek hızda üretebilmesidir.
Veri Hazırlama ve Model Seçimi
Veri Hazırlama
AI tabanlı bir reduced-order modelin başarısı büyük ölçüde veriye bağlıdır. Bu nedenle ROM sürecinin en kritik aşamalarından biri, eğitim verisinin nasıl üretildiğidir. MathWorks tarafında bu iş için iki temel yol vardır: yüksek doğruluklu modelden sentetik veri üretmek veya daha önce toplanmış veriyi uygulamaya almak.
Burada Design of Experiments yaklaşımı kritik hale gelir. Çünkü reduced-order modelin öğreneceği dünya, aslında deney tasarımı ile tanımlanır. Hangi giriş aralıklarının gezileceği, sinyallerin ne kadar çeşitleneceği ve hangi çalışma bölgesinin kapsanacağı; modelin genelleme kabiliyetini doğrudan etkiler.
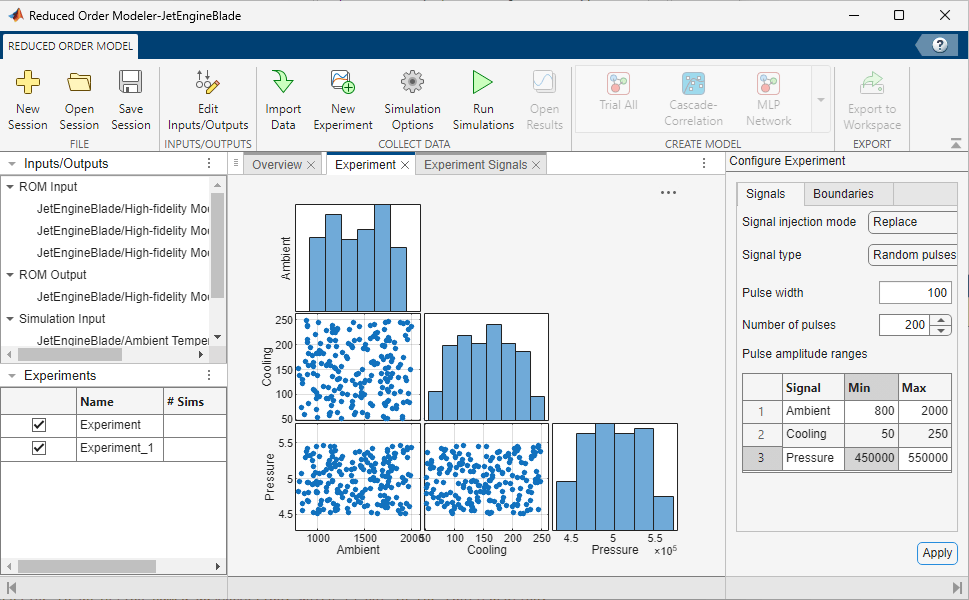
Bu noktada simulation inputs ile ROM inputs ayrımını doğru kurmak da önemlidir. Sistemi dışarıdan sürmek için kullandığınız üst seviye girdiler ile, ROM’un yerine geçeceği pahalı alt sistem bloğunun gerçek girdileri aynı olmak zorunda değildir. Bu ayrım doğru tanımlanırsa veri, daha fiziksel anlamlı ve daha hedefe yönelik hale gelir.
Hangi Tür Data-Driven ROM Kullanılabilir?
Data-driven ROM yaklaşımı genel olarak iki grupta düşünülebilir: time-independent modeller ve dynamic modeller. Time-independent modellerde çıktı yalnızca mevcut girişe bağlı kabul edilir. Başka bir deyişle sistemin hafızası yoktur. Bu tarafta look-up table, surface fitting veya basit MLP yapıları kullanılabilir.
Dynamic modellerde ise sistemin hafızası vardır. Çıktı yalnızca mevcut girdiye değil, geçmiş girdilere ve zaman içindeki evrime de bağlıdır. Isıl gecikmeler, atalet etkileri veya iç durum dinamikleri söz konusuysa bu tür modeller daha uygun hale gelir.
Bu yazıda öne çıkan üç dinamik model ailesi; LSTM, Nonlinear ARX ve Neural State Space yaklaşımıdır.
LSTM ile AI-Based ROM
LSTM, zaman bağımlılıklarını öğrenmek için güçlü bir yapıdır. Sequence input katmanı veriyi sekans olarak modele taşır; LSTM katmanı ise geçmiş bilgiyi state üzerinden taşır. Böylece model, önceki adımları unutmadan zamansal bağımlılıkları öğrenebilir.
Bu yapı özellikle geçmiş girdilerin ve önceki davranışların bugünkü çıktıyı etkilediği sistemlerde anlamlıdır. Bununla birlikte yorumlanabilirlik bazı klasik yöntemlere göre daha sınırlı olabilir ve bazı deployment senaryolarında inference maliyeti farklı modellere göre daha yüksek kalabilir.
Neural State Space ile Fiziksel Davranışa Daha Yakın Bir Öğrenme
Neural State Space yaklaşımında sistem, state denklemleri üzerinden öğrenilir. Bir ağ state’in zaman içinde nasıl evrildiğini; diğer ağ ise bu state’ten çıktının nasıl üretildiğini temsil eder. Ardından bir integratör yardımıyla sistem zaman içinde ilerletilir.
Bu yaklaşım özellikle iç dinamikleri belirgin olan sistemlerde güçlüdür. State-space yapısı sayesinde salt black-box bir modele kıyasla, bazı mühendislik ekipleri için daha doğal bir soyutlama sunabilir. NumberInputLags, NumberOutputLags, NumberLayers, NumberUnits ve SampleRate gibi hiperparametreler de modelin kapasitesi ile zaman çözünürlüğünü belirler.
NLARX: Pratik ve Güçlü Bir Alternatif
Nonlinear ARX modeli, sistemi açık state değişkenleriyle değil; mevcut ve geçmiş girişler ile geçmiş çıkışların oluşturduğu regresörler üzerinden temsil eder. Yani model her zaman adımında geçmiş bilgileri kullanarak yeni çıktıyı üretir.
Bu yaklaşım çoğu mühendislik problemi için güzel bir başlangıç noktası olabilir. Çünkü kurulumu görece pratiktir, dinamik davranışı öğrenebilir ve tamamen derin ağ tabanlı yapılara göre bazı durumlarda daha hızlı eğitim sunabilir.
Model Seçiminde Doğruluk Yeterli mi?
ROM tarafında sık yapılan hatalardan biri yalnızca RMSE gibi bir metriğe odaklanmaktır. Oysa sistem seviyesinde kullanılacak bir model seçerken tek soru, en düşük hatayı kimin verdiği değildir.
Gerçek mühendislik kararında eğitim hızı, inference hızı, model boyutu, yorumlanabilirlik, Simulink entegrasyon kolaylığı ve hedef platform uygunluğu gibi eksenler de en az doğruluk kadar önemlidir. Bu nedenle en iyi model, mutlak olarak değil; bağlama göre belirlenir.
Kontrol tasarımı için seçilecek model ile deployment için seçilecek model her zaman aynı olmayabilir. Asıl mesele, ilgili kullanım senaryosunda doğru hız-doğruluk dengesini kurmaktır.
Model Eğitimi ve Optimizasyon
Dynamic reduced-order model adayları oluşturulduktan sonra bir sonraki kritik adım, bu modellerin yalnızca eğitilmesi değil, aynı zamanda sistematik biçimde iyileştirilmesidir. Bu noktada Experiment Manager app, farklı hiperparametre kombinasyonlarını kontrollü şekilde deneyip sonuçlarını karşılaştırmak için güçlü bir çerçeve sunar.
Örneğin LSTM, NLARX veya Neural State-Space gibi dinamik modeller için katman sayısı, birim sayısı, input-output lag değerleri, öğrenme oranı, mini-batch boyutu ya da eğitim seçenekleri gibi parametreler belirli aralıklarda taranabilir. Experiment Manager, bu kombinasyonları tek tek çalıştırarak her denemenin sonuçlarını kaydeder; böylece hangi ayarların doğruluk, eğitim süresi veya genel performans açısından daha başarılı olduğu sistematik biçimde görülebilir.
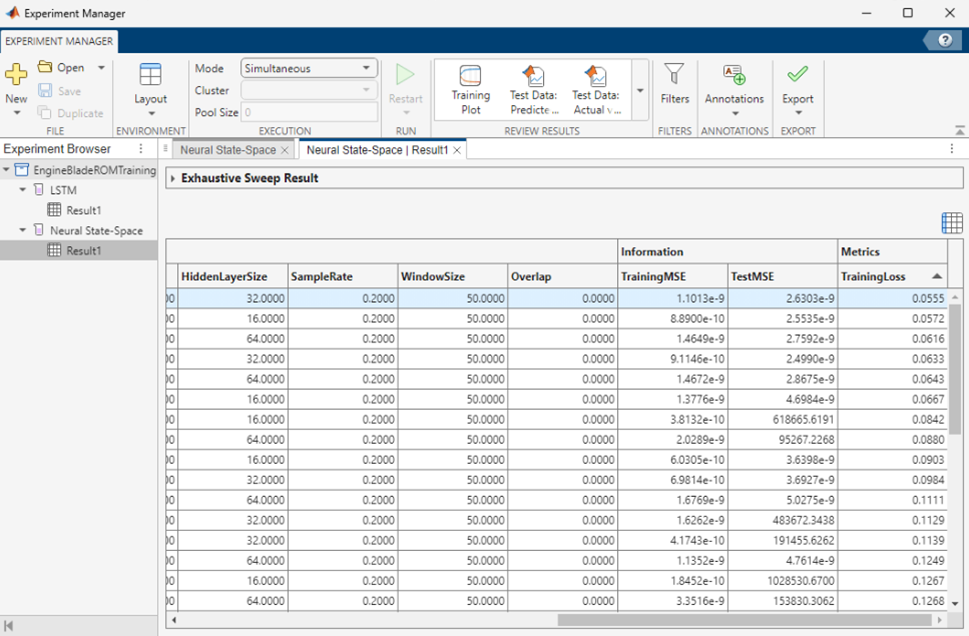
Ayrıca uygulama; klasik parameter sweep yaklaşımına ek olarak rastgele örnekleme ve Bayesian optimization stratejilerini de destekler. Hesaplama maliyeti yüksek olduğunda, Parallel Computing Toolbox ile bu süreç daha da hızlandırılabilir. Experiment Manager birden fazla denemeyi aynı anda paralel çalıştırabilir; özellikle dynamic ROM eğitimlerinde, model sayısı ve deneme alanı büyüdükçe bu paralel yürütme desteği ciddi zaman kazancı sağlar.
Simulink Entegrasyonu ve Karşılaştırma
ROM’un gerçek değeri eğitimden sonra başlar. Eğitilen modelin Simulink’e alınması ve daha büyük sistem modeli içinde kullanılabilmesi gerekir. Bu aşamada amaç yalnızca tekil tahmin başarısını görmek değil; modelin gerçek sistem bağlamındaki davranışını değerlendirmektir.
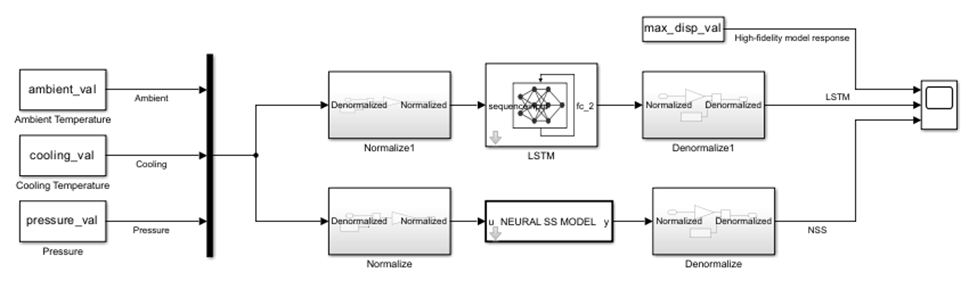
Standalone testte iyi görünen bir model, kapalı çevrim veya daha büyük bir sistem içinde beklenmedik davranışlar gösterebilir. Bu nedenle Simulink entegrasyonu, reduced-order modelin gerçekten mühendislik akışına girdiği adımdır.
High-Fidelity Model ile ROM Nasıl Karşılaştırılır?
Bir reduced-order modelin başarısı iki eksende değerlendirilmelidir: doğruluk ve hız. Yalnızca tahmin eğrilerinin benzemesi yeterli değildir; bu benzerliğin anlamlı bir simülasyon hız kazanımı ile gelmesi gerekir.
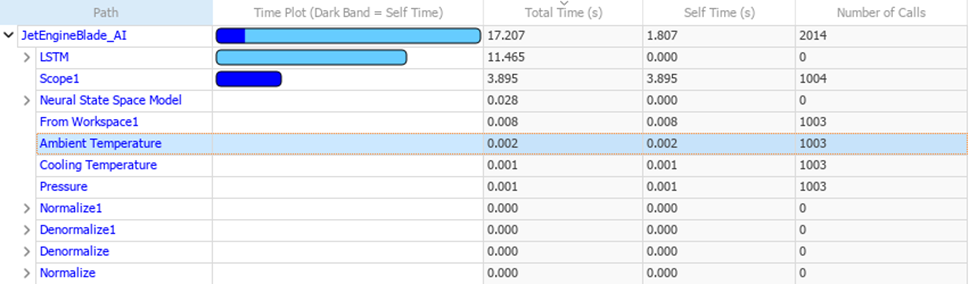
Bu nedenle profiling oldukça önemlidir. Simulink Profiler gibi araçlar, yüksek doğruluklu model ile reduced-order model arasındaki zaman farkını görünür hale getirir. ROM’un değeri de burada netleşir: yaklaşık olarak aynı davranışı çok daha kısa sürede üretmek. Neural state-space modelinin 16 kat daha hızlı olduğunu gözlemleyebiliyoruz.
Verification Neden Gerekli?
AI tabanlı reduced-order model ne kadar hızlı ve doğru görünürse görünsün, özellikle kritik sistemlerde doğrulama olmadan güvenle kullanılamaz. Küçük giriş perturbasyonlarında model kararlı mı, tahmin bandı ne kadar değişiyor ve model dağılım dışı verilerle karşılaştığında nasıl davranıyor gibi sorular önemlidir.
Deep Learning Toolbox Verification Library bu noktada değerli bir katman sunar. Robustness analizi, output bounds değerlendirmesi ve runtime monitoring gibi yaklaşımlar; reduced-order modelin saha kullanımında daha güvenli biçimde değerlendirilmesine yardımcı olur.
Deployment
MathWorks ekosisteminin güçlü olduğu diğer alan, eğitilen AI modellerinin deploy edilebilir hale getirilmesidir. Library-free C code generation ve farklı hedef platform seçenekleri, reduced-order modelin masaüstü prototipi olmaktan çıkıp gerçek zamanlı test veya gömülü çalıştırma senaryolarına taşınmasını mümkün kılar.
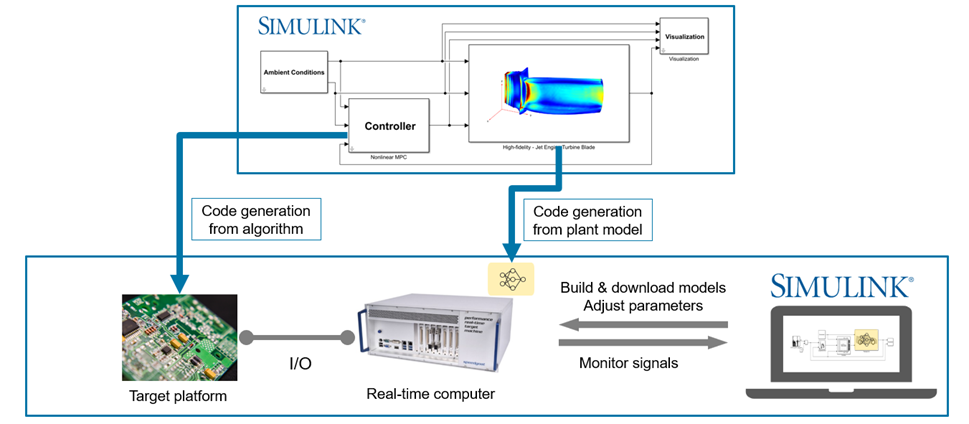
Özellikle HIL akışlarında yüksek doğruluklu plant modelin tamamını gerçek zamanda çalıştırmak çoğu zaman mümkün olmaz. Reduced-order model burada kritik bir çözüm sunar. Eğitilen model hedef platforma aktarılabilir, parametreler ayarlanabilir ve sistem seviyesi entegrasyon gerçek zamanlı test ortamında sürdürülebilir
Kullanıcı Hikayeleri
Endüstriyel kullanım hikâyeleri, ROM’un yalnızca akademik veya demo amaçlı bir konu olmadığını gösterir. Örneğin otomotiv ve güç sistemleri tarafında surrogate modeller ile ciddi hız kazanımları elde edilmiş, performans tahmin akışları daha uygulanabilir hale getirilmiştir. Subaru ve Cummins gibi firmaların çalışamlarına MathWorks sayfasından ulaşabilirsiniz.
Bu tür örnekler, reduced-order modeling yaklaşımının yalnızca teori seviyesinde kalmadığını; mühendislik ekiplerinin günlük geliştirme akışlarında da gerçek karşılığı olduğunu gösterir.
Sonuç
Reduced Order Modeling, yüksek doğruluklu modelleri terk etmek için değil; onları daha geniş mühendislik akışlarında kullanılabilir hale getirmek için vardır. Özellikle AI tabanlı data-driven ROM yaklaşımları, high-fidelity modellerden elde edilen bilgiyi koruyup hesaplama maliyetini ciddi ölçüde azaltabilir.
MATLAB ve Simulink ekosistemi ise bu süreci veri üretiminden model eğitimine, sistem entegrasyonundan verification ve code generation’a kadar tek bir mühendislik hattı içinde ele almayı mümkün kılar.
Bugün birçok ekip için asıl soru artık yüksek doğruluklu modelimizin olup olmadığı değil; bu modeli sistem seviyesinde etkili biçimde nasıl kullanabileceğimizdir. Reduced Order Modeling, bu sorunun en güçlü cevaplarından biridir.